How Search Engine Optimization works - lesson 3
Introduction to how search engine works
To
improve a web page position on SERPs, first of all we have to know how
search engine works. In this article we will expose all about Internet
search engines such as definition of search engines, tutorials on web
crawling, indexing and searching of web search engines.

Fig: Search Engines
Web search engines are special sites on Internet which are
designed to search for information on the world wide web.Search results
are represented in a list consisting of web pages, images, information
and other types of files. There are basically three types of search
engines.
- search engines which are powered by robots (called crawlers; ants or spiders)
- search engines which are powered by human submissions and
- those that are a hybrid of the two.
Robots based search engine use automated software named
as spiders, bots ,crawlers to search the web and analyze the individual
pages, then data collected from each pages are added to the search
engine index. Human powered search engines depend on humans to list a
web page on their database. Manually you have to submit information of a
site to these search engines or directories, then it is subsequently
indexed and catalogued based on your submitted
information. In
Hybrid search engines both crawler-based results or human-powered
listings are used. Here we will discuss only first type of search
engines. All search engines basically perform three tasks:
- They search the web to gather document of web pages and their web addresses using spider or crawler software.
- The indexing software extracts information from the documents, index them based on keyword and store it in a database.
- They allow users to look for words or combinations of words found in that index.
To do their task properly each day search engines have to crawl hundreds of million pages
,
index new web pages and update their old database continuously. Now we
will discuss basic three tasks of search engines in details.
Web crawling of search engines
Search
Engines use automated program called "Spiders" to find new pages or
changed information on the hundreds of millions of web pages. The
process of building lists of the words found on the web sites is called
web crawling.
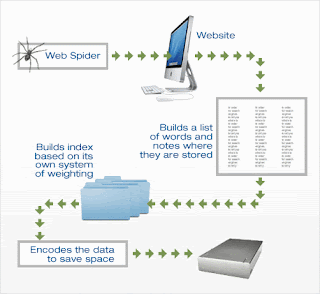
Fig : Web Crawling by Spider
One question may arise, How does any spider start its travels
over the Web? The spider will begin with a high ranking or popular
sites, indexing the words on its pages and then follows every links
found within the sites. In this way, spider starts to travel and visits
the most widely used pages in the web. The content of each pages is
analyzed to determine how it should be indexed. Search engines looks for
relevant keyword of the content of the web pages. Then index that page
with that keyword. When spider looks at a HTML page, it gives special
weight to keywords that appear in :
- In the URL
- In the post Title
- In headings
- In meta tag
- In the description
- High up on the page
- In the ALT tag for images
- In the link text for inbound links
If a site has high page rank, it is spider ed more often
and more deeply. So spider crawl the entire web starting from popular
sites to all links on those sites. But if your site or blog is very new
then there is less probability to get inbound links or backlinks from
higher page ranked sites. Then a question arise, how does spider crawl a
new site or blog? There is a option of manual submission on every
search engines. If you are new site or blog owner then first submit to
popular search engines.
Indexing and Searching
Now
spider have collected the information from the web and search engines
must store those in index database for later queries. The main purpose
of indexing is to find a information as quickly as possible. In simply
search engine could store the keyword and the URL of a page in their
database. But it would not be useful for them. To make efficient and
useful result most search engines store more than just keyword and the
URL. Normally the principle of search engines are not revealed for their
business, so nobody can guarantee a #1 ranking on any SERPs. An engine
might save total numbers that the keyword appears on a page. The engine
might give a rank to each web page depends on the lot of factors such
as no of backlinks, keywords, relevancy of content etc. But each search
engine uses different algorithms on how to index a page. So this is the
one reason why different search engines produce different search lists
for a specific keyword query.
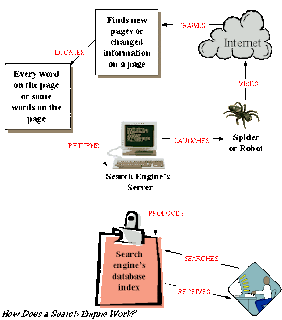
When a user searches specific
keywords on search engine website, the engine returns a listing of
best-matching web pages by examining it's index database. They provide a
short description of the content containing the title and the URL in
the SERPs. To build a complex query most search engines support the use
of Boolean operator that allow to extend the terms of the search. To use
the search engines more efficiently you can follow the instructions
below :
- AND - All the keywords joined by "AND" must be in the web pages or documents. You can replace "AND" with "+" in some search engines.
- OR - At least one of the terms joined by "OR" must be in the web pages or documents. You can replace "OR" with "|" in some search engines.
- NOT - If you want a keyword not showing in the web pages , you can use this operator. Some search engines substitute the operator "-" for the word NOT.
- FOLLOWED BY - One of the keywords must be followed by the other.
- NEAR - One of the terms must be within a specified number of words of the other.
- Quotation Marks - The word between the quotation marks is considered as a phrase. It must be on the web pages
You can find the remainder of these lessons below:










No comments:
Post a Comment